* New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 @ 2009-05-12 16:27 Vladimir Makarov 2009-05-12 18:05 ` Chris Lattner 0 siblings, 1 reply; 30+ messages in thread From: Vladimir Makarov @ 2009-05-12 16:27 UTC (permalink / raw) To: gcc.gcc.gnu.org A few people asked me to do a new comparison of GCC releases and LLVM as the new GCC release and LLVM were out recently. You can find the comparison on http://vmakarov.fedorapeople.org/spec/ The comparison for x86 (32-bit mode) was done on Pentium4 and for x86_64 (64-bit mode) on Core I7. Some changes in the performance were big since GCC 3.2 and it is sometimes hard to see small changes on the posted graphs. Therefore I put original tables used to generate the graphs. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 16:27 New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 Vladimir Makarov @ 2009-05-12 18:05 ` Chris Lattner 2009-05-12 18:21 ` Vladimir Makarov ` (2 more replies) 0 siblings, 3 replies; 30+ messages in thread From: Chris Lattner @ 2009-05-12 18:05 UTC (permalink / raw) To: Vladimir Makarov; +Cc: gcc.gcc.gnu.org, Evan Cheng On May 12, 2009, at 6:56 AM, Vladimir Makarov wrote: > A few people asked me to do a new comparison of GCC releases and > LLVM as the new GCC release and LLVM were out recently. > > You can find the comparison on http://vmakarov.fedorapeople.org/spec/ > > The comparison for x86 (32-bit mode) was done on Pentium4 and for > x86_64 (64-bit mode) on Core I7. > > Some changes in the performance were big since GCC 3.2 and it is > sometimes hard to see small changes on the posted graphs. > Therefore I put original tables used to generate the graphs. Looking at the llvm 2.5 vs gcc 4.4 comparison is very interesting, thank you for putting this together Vladimir! I find these numbers particularly interesting because you're comparing simple options like - O2 and -O3 instead of the crazy spec tuning mix :). This is much more likely to be representative of what real users will get on their apps. Some random thoughts: 1. I have a hard time understanding the code size numbers. Does 10% mean that GCC is generating 10% bigger or 10% smaller code than llvm? 2. You change two variables in your configurations: micro architecture and pointer size. Would you be willing to run x86-32 Core i7 numbers as well? LLVM in particular is completely untuned for the (really old and quirky) "netburst" architecture, but I'm interested to see how it runs for you on more modern Core i7 or Core2 processors in 32-bit mode. 3. Your SPEC FP benchmarks tell me two things: GCC 4.4's fortran support is dramatically better than 4.2's (which llvm 2.5 uses), and your art/mgrid hacks apparently do great stuff :). 4. Your SPEC INT numbers are more interesting to me. It looks like you guys have some significant wins in 175.vpr, 197.crafty, and other benchmarks. At some point, I'll have to see what you guys are doing :) Thanks for the info, great stuff! -Chris ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 18:05 ` Chris Lattner @ 2009-05-12 18:21 ` Vladimir Makarov 2009-05-12 19:25 ` Chris Lattner 2009-05-12 19:41 ` Vladimir Makarov 2009-05-12 18:29 ` Joseph S. Myers 2009-05-13 6:42 ` Steven Bosscher 2 siblings, 2 replies; 30+ messages in thread From: Vladimir Makarov @ 2009-05-12 18:21 UTC (permalink / raw) To: Chris Lattner; +Cc: gcc.gcc.gnu.org, Evan Cheng Chris Lattner wrote: > > On May 12, 2009, at 6:56 AM, Vladimir Makarov wrote: > >> A few people asked me to do a new comparison of GCC releases and LLVM >> as the new GCC release and LLVM were out recently. >> >> You can find the comparison on http://vmakarov.fedorapeople.org/spec/ >> >> The comparison for x86 (32-bit mode) was done on Pentium4 and for >> x86_64 (64-bit mode) on Core I7. >> >> Some changes in the performance were big since GCC 3.2 and it is >> sometimes hard to see small changes on the posted graphs. Therefore >> I put original tables used to generate the graphs. > > Looking at the llvm 2.5 vs gcc 4.4 comparison is very interesting, > thank you for putting this together Vladimir! I find these numbers > particularly interesting because you're comparing simple options like > -O2 and -O3 instead of the crazy spec tuning mix :). This is much > more likely to be representative of what real users will get on their > apps. > > Some random thoughts: > > 1. I have a hard time understanding the code size numbers. Does 10% > mean that GCC is generating 10% bigger or 10% smaller code than llvm? > The change is reported relative to LLVM. So 10% means that GCC generates 10% bigger code than LLVM and -10% means that GCC generates 10% less code. > 2. You change two variables in your configurations: micro architecture > and pointer size. Would you be willing to run x86-32 Core i7 numbers > as well? LLVM in particular is completely untuned for the (really old > and quirky) "netburst" architecture, but I'm interested to see how it > runs for you on more modern Core i7 or Core2 processors in 32-bit mode. > I used the same processor (P4) and options for x86 as for the GCC release comparison. I did not know that LLVM is badly tuned for P4, sorry. I could do the same comparison for x86 on Core i7 without specific tuning (there is no tuning for i7 yet) but it takes a lot of time. May be it will be ready on next week. > 3. Your SPEC FP benchmarks tell me two things: GCC 4.4's fortran > support is dramatically better than 4.2's (which llvm 2.5 uses), and > your art/mgrid hacks apparently do great stuff :). > > 4. Your SPEC INT numbers are more interesting to me. It looks like > you guys have some significant wins in 175.vpr, 197.crafty, and other > benchmarks. At some point, I'll have to see what you guys are doing :) > > Thanks for the info, great stuff! > > -Chris > ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 18:21 ` Vladimir Makarov @ 2009-05-12 19:25 ` Chris Lattner 2009-05-12 22:48 ` Rafael Espindola 2009-05-12 19:41 ` Vladimir Makarov 1 sibling, 1 reply; 30+ messages in thread From: Chris Lattner @ 2009-05-12 19:25 UTC (permalink / raw) To: Vladimir Makarov; +Cc: gcc.gcc.gnu.org, Evan Cheng On May 12, 2009, at 11:05 AM, Vladimir Makarov wrote: > Chris Lattner wrote: >> On May 12, 2009, at 6:56 AM, Vladimir Makarov wrote: >> >>> A few people asked me to do a new comparison of GCC releases and >>> LLVM as the new GCC release and LLVM were out recently. >>> >>> You can find the comparison on http://vmakarov.fedorapeople.org/ >>> spec/ >>> >>> The comparison for x86 (32-bit mode) was done on Pentium4 and for >>> x86_64 (64-bit mode) on Core I7. >>> >>> Some changes in the performance were big since GCC 3.2 and it is >>> sometimes hard to see small changes on the posted graphs. >>> Therefore I put original tables used to generate the graphs. >> >> Looking at the llvm 2.5 vs gcc 4.4 comparison is very interesting, >> thank you for putting this together Vladimir! I find these numbers >> particularly interesting because you're comparing simple options >> like -O2 and -O3 instead of the crazy spec tuning mix :). This is >> much more likely to be representative of what real users will get >> on their apps. >> >> Some random thoughts: >> >> 1. I have a hard time understanding the code size numbers. Does >> 10% mean that GCC is generating 10% bigger or 10% smaller code than >> llvm? >> > The change is reported relative to LLVM. So 10% means that GCC > generates 10% bigger code than LLVM and -10% means that GCC > generates 10% less code. Ok! It is interesting that GCC seems to generate consistently larger code at both -O2 and -O3 in x86-64 mode (over 20% larger in -O3). Perhaps that also is impacting the compile time numbers as well. >> 2. You change two variables in your configurations: micro >> architecture and pointer size. Would you be willing to run x86-32 >> Core i7 numbers as well? LLVM in particular is completely untuned >> for the (really old and quirky) "netburst" architecture, but I'm >> interested to see how it runs for you on more modern Core i7 or >> Core2 processors in 32-bit mode. >> > I used the same processor (P4) and options for x86 as for the GCC > release comparison. I did not know that LLVM is badly tuned for P4, > sorry. I could do the same comparison for x86 on Core i7 without > specific tuning (there is no tuning for i7 yet) but it takes a lot > of time. May be it will be ready on next week. No problem at all, I appreciate you running the numbers! It would also be very interesting to include LLVM's LTO support, which gives a pretty dramatic win on SPEC. However, I don't know how difficult it is to use on linux (on the mac, you just pass -O4 at compile time, and everything works). I've heard that Gold has a new plugin to make LTO transparent on linux as well, but I have no experience with it, and it is probably more trouble than you want to take. Does gcc 4.4 include the LTO branch yet? -Chris > >> 3. Your SPEC FP benchmarks tell me two things: GCC 4.4's fortran >> support is dramatically better than 4.2's (which llvm 2.5 uses), >> and your art/mgrid hacks apparently do great stuff :). >> >> 4. Your SPEC INT numbers are more interesting to me. It looks like >> you guys have some significant wins in 175.vpr, 197.crafty, and >> other benchmarks. At some point, I'll have to see what you guys >> are doing :) >> >> Thanks for the info, great stuff! >> >> -Chris >> > ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 19:25 ` Chris Lattner @ 2009-05-12 22:48 ` Rafael Espindola 0 siblings, 0 replies; 30+ messages in thread From: Rafael Espindola @ 2009-05-12 22:48 UTC (permalink / raw) To: Chris Lattner; +Cc: Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng > It would also be very interesting to include LLVM's LTO support, which gives > a pretty dramatic win on SPEC. However, I don't know how difficult it is to > use on linux (on the mac, you just pass -O4 at compile time, and everything > works). I've heard that Gold has a new plugin to make LTO transparent on > linux as well, but I have no experience with it, and it is probably more > trouble than you want to take. Does gcc 4.4 include the LTO branch yet? For spec all that you (should) need is to link with a gold with plugins enabled and pass -use-gold-plugin to llvm-gcc. For software that uses static libraries you will also need the bfd plugin support (currently in code review). I am going on vacation tomorrow, but might read my mail from time to time. Ping me if you need help. The current trunk includes some patches from LTO, but not the streamer. > -Chris Cheers, -- Rafael Avila de Espindola Google | Gordon House | Barrow Street | Dublin 4 | Ireland Registered in Dublin, Ireland | Registration Number: 368047 ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 18:21 ` Vladimir Makarov 2009-05-12 19:25 ` Chris Lattner @ 2009-05-12 19:41 ` Vladimir Makarov 2009-05-13 12:11 ` Duncan Sands 1 sibling, 1 reply; 30+ messages in thread From: Vladimir Makarov @ 2009-05-12 19:41 UTC (permalink / raw) To: Chris Lattner; +Cc: gcc.gcc.gnu.org, Evan Cheng Vladimir Makarov wrote: > Chris Lattner wrote: >> 2. You change two variables in your configurations: micro >> architecture and pointer size. Would you be willing to run x86-32 >> Core i7 numbers as well? LLVM in particular is completely untuned >> for the (really old and quirky) "netburst" architecture, but I'm >> interested to see how it runs for you on more modern Core i7 or Core2 >> processors in 32-bit mode. >> > I used the same processor (P4) and options for x86 as for the GCC > release comparison. I was wrong here GCC-LLVM comparison does not use -mtune=pentium4 as it was used for GCC releases. So default x86 tunings for the compilers were used for the 32-bit comparison. Still the results might look different on Core i7. Sorry, I missed to mention that I used an additional option -mpc64 for 32-bit GCC4.4. It is not possible to generate SPECFP2000 expected results by GCC4.4 without this option. LLVM does not support this option. And this option can significantly improve the performance. So 32-bit comparison of SPECFP2000 should be taken with a grain of salt. I've just corrected page http://vmakarov.fedorapeople.org/spec/llvmgcc32.html by adding these comments. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 19:41 ` Vladimir Makarov @ 2009-05-13 12:11 ` Duncan Sands 2009-05-13 12:38 ` Richard Guenther 2009-05-13 20:06 ` Evan Cheng 0 siblings, 2 replies; 30+ messages in thread From: Duncan Sands @ 2009-05-13 12:11 UTC (permalink / raw) To: gcc; +Cc: Vladimir Makarov, Chris Lattner, Evan Cheng Hi, > Sorry, I missed to mention that I used an additional option -mpc64 for > 32-bit GCC4.4. It is not possible to generate SPECFP2000 expected > results by GCC4.4 without this option. LLVM does not support this > option. And this option can significantly improve the performance. So > 32-bit comparison of SPECFP2000 should be taken with a grain of salt. what does -mpc64 do exactly? The gcc docs say: `-mpc64' rounds the the significands of results of floating-point operations to 53 bits (double precision) Does this mean that a rounding operation is performed after each fp operation, or that optimizations are permitted that don't result in accurate extended double precision values as long as they are correct to 53 bits, or something else? The LLVM code generators have an option called -limit-float-precision: -limit-float-precision=<uint> - Generate low-precision inline sequences for some float libcalls I'm not sure what it does exactly, but perhaps it is similar to -mpc64? Ciao, Duncan. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 12:11 ` Duncan Sands @ 2009-05-13 12:38 ` Richard Guenther 2009-05-13 12:55 ` Joseph S. Myers 2009-05-13 13:51 ` Duncan Sands 2009-05-13 20:06 ` Evan Cheng 1 sibling, 2 replies; 30+ messages in thread From: Richard Guenther @ 2009-05-13 12:38 UTC (permalink / raw) To: Duncan Sands; +Cc: gcc, Vladimir Makarov, Chris Lattner, Evan Cheng On Wed, May 13, 2009 at 1:51 PM, Duncan Sands <duncan.sands@math.u-psud.fr> wrote: > Hi, > >> Sorry, I missed to mention that I used an additional option -mpc64 for >> 32-bit GCC4.4. It is not possible to generate SPECFP2000 expected >> results by GCC4.4 without this option. LLVM does not support this >> option. And this option can significantly improve the performance. So >> 32-bit comparison of SPECFP2000 should be taken with a grain of salt. > > what does -mpc64 do exactly? The gcc docs say: > `-mpc64' rounds the the significands of results of floating-point operations to 53 bits (double precision) > Does this mean that a rounding operation is performed after each fp > operation, or that optimizations are permitted that don't result in > accurate extended double precision values as long as they are correct > to 53 bits, or something else? > > The LLVM code generators have an option called -limit-float-precision: > -limit-float-precision=<uint> - Generate low-precision inline sequences for some float libcalls > I'm not sure what it does exactly, but perhaps it is similar to -mpc64? -mpc64 sets the x87 floating point control register to not use the 80bit extended precision. This causes some x87 floating point operations to operate faster and there are no issues with the extra roundings you get when storing an 80bit precision register to a 64bit memory location. Does LLVM support x87 arithmetic at all or does it default to SSE arithmetic in 32bits? I guess using SSE math for both would be a more fair comparison? Richard. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 12:38 ` Richard Guenther @ 2009-05-13 12:55 ` Joseph S. Myers 2009-05-13 13:51 ` Duncan Sands 1 sibling, 0 replies; 30+ messages in thread From: Joseph S. Myers @ 2009-05-13 12:55 UTC (permalink / raw) To: Richard Guenther Cc: Duncan Sands, gcc, Vladimir Makarov, Chris Lattner, Evan Cheng On Wed, 13 May 2009, Richard Guenther wrote: > -mpc64 sets the x87 floating point control register to not use the 80bit > extended precision. This causes some x87 floating point operations > to operate faster and there are no issues with the extra roundings you > get when storing an 80bit precision register to a 64bit memory location. Note that this is purely a link-time option; it does not cause TARGET_96_ROUND_53_LONG_DOUBLE to be set so the compiler will not know internally how long double behaves in the processor. Note also that you still have the extended exponent range and associated issues with storing to memory with that (including extra roundings for subnormals). -- Joseph S. Myers joseph@codesourcery.com ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 12:38 ` Richard Guenther 2009-05-13 12:55 ` Joseph S. Myers @ 2009-05-13 13:51 ` Duncan Sands 2009-05-26 12:27 ` Chris Lattner 1 sibling, 1 reply; 30+ messages in thread From: Duncan Sands @ 2009-05-13 13:51 UTC (permalink / raw) To: Richard Guenther; +Cc: gcc, Vladimir Makarov, Chris Lattner, Evan Cheng Hi Richard, > -mpc64 sets the x87 floating point control register to not use the 80bit > extended precision. This causes some x87 floating point operations > to operate faster and there are no issues with the extra roundings you > get when storing an 80bit precision register to a 64bit memory location. I see, thanks for the explanation. > Does LLVM support x87 arithmetic at all or does it default to SSE > arithmetic in 32bits? I guess using SSE math for both would be a more > fair comparison? LLVM does support the x86 floating point stack, though it doesn't support all asm expressions for it (which is why llvm-gcc disables math inlines). My understanding is that no effort has been made to produce optimal code when using the x86 fp stack, and all the effort when into SSE instead. Ciao, Duncan. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 13:51 ` Duncan Sands @ 2009-05-26 12:27 ` Chris Lattner 2009-05-26 13:48 ` Vincent Lefevre 2009-05-28 23:00 ` Joseph S. Myers 0 siblings, 2 replies; 30+ messages in thread From: Chris Lattner @ 2009-05-26 12:27 UTC (permalink / raw) To: Duncan Sands; +Cc: Richard Guenther, gcc, Vladimir Makarov, Evan Cheng On May 13, 2009, at 5:26 AM, Duncan Sands wrote: > Hi Richard, > >> -mpc64 sets the x87 floating point control register to not use the >> 80bit >> extended precision. This causes some x87 floating point operations >> to operate faster and there are no issues with the extra roundings >> you >> get when storing an 80bit precision register to a 64bit memory >> location. However, this does break long double, right? >> Does LLVM support x87 arithmetic at all or does it default to SSE >> arithmetic in 32bits? I guess using SSE math for both would be a >> more >> fair comparison? > > LLVM does support the x86 floating point stack, though it doesn't > support > all asm expressions for it (which is why llvm-gcc disables math > inlines). > My understanding is that no effort has been made to produce optimal > code > when using the x86 fp stack, and all the effort when into SSE instead. As long as you configure llvm-gcc with --with-arch=pentium-4 or later, you should be fine. I personally use --with-arch=nocona. -Chris ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-26 12:27 ` Chris Lattner @ 2009-05-26 13:48 ` Vincent Lefevre 2009-05-28 23:00 ` Joseph S. Myers 1 sibling, 0 replies; 30+ messages in thread From: Vincent Lefevre @ 2009-05-26 13:48 UTC (permalink / raw) To: gcc On 2009-05-25 12:53:49 -0700, Chris Lattner wrote: > On May 13, 2009, at 5:26 AM, Duncan Sands wrote: >>> -mpc64 sets the x87 floating point control register to not use the >>> 80bit extended precision. This causes some x87 floating point >>> operations to operate faster and there are no issues with the >>> extra roundings you get when storing an 80bit precision register >>> to a 64bit memory location. > > However, this does break long double, right? Unless the parameters associated with long double (among LDBL_MANT_DIG, LDBL_DIG, LDBL_MIN_EXP, LDBL_MIN_10_EXP, LDBL_MAX_EXP, LDBL_MAX_10_EXP, LDBL_MAX, LDBL_EPSILON, LDBL_MIN) are changed accordingly. -- Vincent Lefèvre <vincent@vinc17.org> - Web: <http://www.vinc17.org/> 100% accessible validated (X)HTML - Blog: <http://www.vinc17.org/blog/> Work: CR INRIA - computer arithmetic / Arenaire project (LIP, ENS-Lyon) ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-26 12:27 ` Chris Lattner 2009-05-26 13:48 ` Vincent Lefevre @ 2009-05-28 23:00 ` Joseph S. Myers 1 sibling, 0 replies; 30+ messages in thread From: Joseph S. Myers @ 2009-05-28 23:00 UTC (permalink / raw) To: Chris Lattner Cc: Duncan Sands, Richard Guenther, gcc, Vladimir Makarov, Evan Cheng On Mon, 25 May 2009, Chris Lattner wrote: > On May 13, 2009, at 5:26 AM, Duncan Sands wrote: > > > Hi Richard, > > > > > -mpc64 sets the x87 floating point control register to not use the 80bit > > > extended precision. This causes some x87 floating point operations > > > to operate faster and there are no issues with the extra roundings you > > > get when storing an 80bit precision register to a 64bit memory location. > > However, this does break long double, right? I already said in <http://gcc.gnu.org/ml/gcc/2009-05/msg00341.html> that it is a purely link-time option that does not cause TARGET_96_ROUND_53_LONG_DOUBLE to be set; fixing that would make long double behave correctly, although not necessarily calls to libgcc, libstdc++, libm or other library functions that did not expect to be called in the different mode, unless extra multilibs built to expect that mode are added (and the source code to libraries such as libm adjusted to handle this). -- Joseph S. Myers joseph@codesourcery.com ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 12:11 ` Duncan Sands 2009-05-13 12:38 ` Richard Guenther @ 2009-05-13 20:06 ` Evan Cheng 1 sibling, 0 replies; 30+ messages in thread From: Evan Cheng @ 2009-05-13 20:06 UTC (permalink / raw) To: Duncan Sands; +Cc: gcc, Vladimir Makarov, Chris Lattner On May 13, 2009, at 4:51 AM, Duncan Sands wrote: > Hi, > >> Sorry, I missed to mention that I used an additional option -mpc64 >> for >> 32-bit GCC4.4. It is not possible to generate SPECFP2000 expected >> results by GCC4.4 without this option. LLVM does not support this >> option. And this option can significantly improve the >> performance. So >> 32-bit comparison of SPECFP2000 should be taken with a grain of salt. > > what does -mpc64 do exactly? The gcc docs say: > `-mpc64' rounds the the significands of results of floating-point > operations to 53 bits (double precision) > Does this mean that a rounding operation is performed after each fp > operation, or that optimizations are permitted that don't result in > accurate extended double precision values as long as they are correct > to 53 bits, or something else? > > The LLVM code generators have an option called -limit-float-precision: > -limit-float-precision=<uint> - Generate low-precision inline > sequences for some float libcalls > I'm not sure what it does exactly, but perhaps it is similar to - > mpc64? No, that inline a small set of libcalls into sequences code that implement low precision math (6, 8, 12 bits). Evan > > Ciao, > > Duncan. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 18:05 ` Chris Lattner 2009-05-12 18:21 ` Vladimir Makarov @ 2009-05-12 18:29 ` Joseph S. Myers 2009-05-12 18:42 ` Vladimir Makarov 2009-05-13 8:44 ` Andi Kleen 2009-05-13 6:42 ` Steven Bosscher 2 siblings, 2 replies; 30+ messages in thread From: Joseph S. Myers @ 2009-05-12 18:29 UTC (permalink / raw) To: Chris Lattner; +Cc: Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng On Tue, 12 May 2009, Chris Lattner wrote: > 1. I have a hard time understanding the code size numbers. Does 10% mean that > GCC is generating 10% bigger or 10% smaller code than llvm? I have a different comment on the code size numbers: could we have comparisons of code size for -Os rather than (or in addition to) -O2 and -O3? If someone is particularly concerned with code size, -Os is what they are expected to use. -- Joseph S. Myers joseph@codesourcery.com ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 18:29 ` Joseph S. Myers @ 2009-05-12 18:42 ` Vladimir Makarov 2009-05-13 8:44 ` Andi Kleen 1 sibling, 0 replies; 30+ messages in thread From: Vladimir Makarov @ 2009-05-12 18:42 UTC (permalink / raw) To: Joseph S. Myers; +Cc: Chris Lattner, gcc.gcc.gnu.org, Evan Cheng Joseph S. Myers wrote: > On Tue, 12 May 2009, Chris Lattner wrote: > > >> 1. I have a hard time understanding the code size numbers. Does 10% mean that >> GCC is generating 10% bigger or 10% smaller code than llvm? >> > > I have a different comment on the code size numbers: could we have > comparisons of code size for -Os rather than (or in addition to) -O2 and > -O3? If someone is particularly concerned with code size, -Os is what > they are expected to use. > > Thanks for pointing this, Joseph. Yes, it would be interesting to see how GCC code size is changed with -Os (as the performance too). But probably it is even more interesting for embedded processors. When I am less busy, I'll try to do it. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 18:29 ` Joseph S. Myers 2009-05-12 18:42 ` Vladimir Makarov @ 2009-05-13 8:44 ` Andi Kleen 2009-05-13 9:56 ` Jakub Jelinek 2009-05-13 11:32 ` Paolo Bonzini 1 sibling, 2 replies; 30+ messages in thread From: Andi Kleen @ 2009-05-13 8:44 UTC (permalink / raw) To: Joseph S. Myers Cc: Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng "Joseph S. Myers" <joseph@codesourcery.com> writes: > On Tue, 12 May 2009, Chris Lattner wrote: > >> 1. I have a hard time understanding the code size numbers. Does 10% mean that >> GCC is generating 10% bigger or 10% smaller code than llvm? > > I have a different comment on the code size numbers: could we have > comparisons of code size for -Os rather than (or in addition to) -O2 and > -O3? If someone is particularly concerned with code size, -Os is what > they are expected to use. It's a slippery slope that -O2 is getting so bad regarding code size. What should people do who need performance, but cannot completely disregard code size (and can't use profile feedback for some reason). Also with limited caches code size for large programs typically tends to affect performance too. In my experience -Os has some significant drawbacks because it prioritizes everything code size over everything else. For example one -Os problem case we ran into was on x86 it always uses a fully generic hardware division when dividing by constant even for cases where you can generate a much faster sequence by spending a few more bytes. Also it disables a lot of other useful optimizations. -Andi -- ak@linux.intel.com -- Speaking for myself only. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 8:44 ` Andi Kleen @ 2009-05-13 9:56 ` Jakub Jelinek 2009-05-13 11:32 ` Paolo Bonzini 1 sibling, 0 replies; 30+ messages in thread From: Jakub Jelinek @ 2009-05-13 9:56 UTC (permalink / raw) To: Andi Kleen Cc: Joseph S. Myers, Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng On Wed, May 13, 2009 at 09:33:20AM +0200, Andi Kleen wrote: > "Joseph S. Myers" <joseph@codesourcery.com> writes: > > > On Tue, 12 May 2009, Chris Lattner wrote: > > > >> 1. I have a hard time understanding the code size numbers. Does 10% mean that > >> GCC is generating 10% bigger or 10% smaller code than llvm? > > > > I have a different comment on the code size numbers: could we have > > comparisons of code size for -Os rather than (or in addition to) -O2 and > > -O3? If someone is particularly concerned with code size, -Os is what > > they are expected to use. > > It's a slippery slope that -O2 is getting so bad regarding > code size. What should people do who need performance, but cannot > completely disregard code size (and can't use profile feedback for > some reason). For x86_64/i?86 http://gcc.gnu.org/ml/gcc-patches/2009-05/msg00702.html patch might buy back around 2% for -O2 code (at least it does so for cc1plus binary), and perhaps improving min_insn_size might give further code size improvements at -O2. Jakub ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 8:44 ` Andi Kleen 2009-05-13 9:56 ` Jakub Jelinek @ 2009-05-13 11:32 ` Paolo Bonzini 2009-05-13 11:35 ` Paolo Bonzini ` (2 more replies) 1 sibling, 3 replies; 30+ messages in thread From: Paolo Bonzini @ 2009-05-13 11:32 UTC (permalink / raw) To: Andi Kleen Cc: Joseph S. Myers, Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng Andi Kleen wrote: > "Joseph S. Myers" <joseph@codesourcery.com> writes: > >> On Tue, 12 May 2009, Chris Lattner wrote: >> >>> 1. I have a hard time understanding the code size numbers. Does 10% mean that >>> GCC is generating 10% bigger or 10% smaller code than llvm? >> I have a different comment on the code size numbers: could we have >> comparisons of code size for -Os rather than (or in addition to) -O2 and >> -O3? If someone is particularly concerned with code size, -Os is what >> they are expected to use. > > It's a slippery slope that -O2 is getting so bad regarding > code size. What should people do who need performance, but cannot > completely disregard code size (and can't use profile feedback for > some reason). From looking http://vmakarov.fedorapeople.org/spec/I2Size32.png it does not look that bad at all. For SpecFP it is different, but code size is rarely a problem in FP benchmarks (hot loops are really small or really huge anyway). So it looks like we're doing the right thing in that respect. Rather, we should seriously understand what caused the compilation time jump in 4.2, and whether those are still a problem. We made a good job in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with speedups from other changes; and 4.4 while slower than 4.3 at least stays below 4.2. But, 4.2 was a disaster for compilation time. Paolo ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 11:32 ` Paolo Bonzini @ 2009-05-13 11:35 ` Paolo Bonzini 2009-05-13 12:07 ` Andi Kleen 2009-05-13 16:16 ` Vladimir Makarov 2 siblings, 0 replies; 30+ messages in thread From: Paolo Bonzini @ 2009-05-13 11:35 UTC (permalink / raw) To: gcc Cc: Joseph S. Myers, Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng Andi Kleen wrote: > "Joseph S. Myers" <joseph@codesourcery.com> writes: > >> On Tue, 12 May 2009, Chris Lattner wrote: >> >>> 1. I have a hard time understanding the code size numbers. Does 10% mean that >>> GCC is generating 10% bigger or 10% smaller code than llvm? >> I have a different comment on the code size numbers: could we have >> comparisons of code size for -Os rather than (or in addition to) -O2 and >> -O3? If someone is particularly concerned with code size, -Os is what >> they are expected to use. > > It's a slippery slope that -O2 is getting so bad regarding > code size. What should people do who need performance, but cannot > completely disregard code size (and can't use profile feedback for > some reason). From looking http://vmakarov.fedorapeople.org/spec/I2Size32.png it does not look that bad at all. For SpecFP it is different, but code size is rarely a problem in FP benchmarks (hot loops are really small or really huge anyway). So it looks like we're doing the right thing in that respect. Rather, we should seriously understand what caused the compilation time jump in 4.2, and whether those are still a problem. We made a good job in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with speedups from other changes; and 4.4 while slower than 4.3 at least stays below 4.2. But, 4.2 was a disaster for compilation time. Paolo ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 11:32 ` Paolo Bonzini 2009-05-13 11:35 ` Paolo Bonzini @ 2009-05-13 12:07 ` Andi Kleen 2009-05-13 12:23 ` Steven Bosscher 2009-05-13 15:14 ` Paolo Bonzini 2009-05-13 16:16 ` Vladimir Makarov 2 siblings, 2 replies; 30+ messages in thread From: Andi Kleen @ 2009-05-13 12:07 UTC (permalink / raw) To: Paolo Bonzini Cc: Andi Kleen, Joseph S. Myers, Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng > From looking http://vmakarov.fedorapeople.org/spec/I2Size32.png it does > not look that bad at all. For SpecFP it is different, but code size is The code size seems to be much worse than LLVM at least, unless I misread the graphs. Also my comment was in regard of the suggestion to try -Os -- -Os is not the answer for -O2 code size regressions. > Rather, we should seriously understand what caused the compilation time > jump in 4.2, and whether those are still a problem. We made a good job > in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with > speedups from other changes; and 4.4 while slower than 4.3 at least > stays below 4.2. But, 4.2 was a disaster for compilation time. Yes that would be useful, although I admit for me personally make -j and icecream do a pretty good job at hiding that pain. -Andi -- ak@linux.intel.com -- Speaking for myself only. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 12:07 ` Andi Kleen @ 2009-05-13 12:23 ` Steven Bosscher 2009-05-13 12:27 ` Dave Korn 2009-05-13 15:14 ` Paolo Bonzini 1 sibling, 1 reply; 30+ messages in thread From: Steven Bosscher @ 2009-05-13 12:23 UTC (permalink / raw) To: Andi Kleen Cc: Paolo Bonzini, Joseph S. Myers, Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng On Wed, May 13, 2009 at 1:41 PM, Andi Kleen <andi@firstfloor.org> wrote: >> Rather, we should seriously understand what caused the compilation time >> jump in 4.2, and whether those are still a problem. We made a good job >> in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with >> speedups from other changes; and 4.4 while slower than 4.3 at least >> stays below 4.2. But, 4.2 was a disaster for compilation time. > > Yes that would be useful, although I admit for me personally > make -j and icecream do a pretty good job at hiding that pain. Yes, well... Given the continuous complaints/bashes from some of your fellow kernel hackers and many others, it still is still important to address the compilation time issues. There still is enough low-hanging fruit. Ciao! Steven ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 12:23 ` Steven Bosscher @ 2009-05-13 12:27 ` Dave Korn 0 siblings, 0 replies; 30+ messages in thread From: Dave Korn @ 2009-05-13 12:27 UTC (permalink / raw) To: Steven Bosscher Cc: Andi Kleen, Paolo Bonzini, Joseph S. Myers, Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng Steven Bosscher wrote: > On Wed, May 13, 2009 at 1:41 PM, Andi Kleen <andi@firstfloor.org> wrote: >>> Rather, we should seriously understand what caused the compilation time >>> jump in 4.2, and whether those are still a problem. We made a good job >>> in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with >>> speedups from other changes; and 4.4 while slower than 4.3 at least >>> stays below 4.2. But, 4.2 was a disaster for compilation time. >> Yes that would be useful, although I admit for me personally >> make -j and icecream do a pretty good job at hiding that pain. > > Yes, well... > > Given the continuous complaints/bashes from some of your fellow kernel > hackers and many others, it still is still important to address the > compilation time issues. There still is enough low-hanging fruit. Us Cygwin folks will not be complaining about any improvements in compile-time issues either :-) We have a fair amount of emulation overhead to live with as it is. cheers, DaveK ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 12:07 ` Andi Kleen 2009-05-13 12:23 ` Steven Bosscher @ 2009-05-13 15:14 ` Paolo Bonzini 1 sibling, 0 replies; 30+ messages in thread From: Paolo Bonzini @ 2009-05-13 15:14 UTC (permalink / raw) To: Andi Kleen Cc: Joseph S. Myers, Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng Andi Kleen wrote: >> From looking http://vmakarov.fedorapeople.org/spec/I2Size32.png it does >> not look that bad at all. For SpecFP it is different, but code size is > > The code size seems to be much worse than LLVM at least, unless > I misread the graphs. Not really, see http://vmakarov.fedorapeople.org/spec/GLI2Size32.png and http://vmakarov.fedorapeople.org/spec/GLF2Size32.png That said, the LLVM results are totally interesting and kudos must go to the LLVM people. (I would love to have a DAG-based instruction selection pass...) Paolo ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 11:32 ` Paolo Bonzini 2009-05-13 11:35 ` Paolo Bonzini 2009-05-13 12:07 ` Andi Kleen @ 2009-05-13 16:16 ` Vladimir Makarov 2009-05-13 17:59 ` Jan Hubicka 2009-05-15 20:19 ` Toon Moene 2 siblings, 2 replies; 30+ messages in thread From: Vladimir Makarov @ 2009-05-13 16:16 UTC (permalink / raw) To: Paolo Bonzini; +Cc: gcc, Joseph S. Myers, Chris Lattner, Evan Cheng Paolo Bonzini wrote: > > Rather, we should seriously understand what caused the compilation time > jump in 4.2, and whether those are still a problem. We made a good job > in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with > speedups from other changes; and 4.4 while slower than 4.3 at least > stays below 4.2. But, 4.2 was a disaster for compilation time. > > It was interesting for me that GCC4.4 is faster than GCC4.3 on Intel Core I7. This is not true for most other processors (at least for P4, Core2, Power4/5/6 etc). Intel Core I7 has 3rd level big and fast cache and memory controller on the chip. I guess that slowdown in GCC is mostly because of data and/or code locality. Fortunately, GCC4.5 will be 5% faster because of Richard Guenter's work on improving aliasing (of course if it will be not eaten by a new optimization). People are complaining about GCC compilation speed and of course we should work on its speedup. But GCC is not so bad, for example SUN Studio compiler is almost 2 times slower than GCC. IMHO, GCC performace is still #1 priority for us (although people working on embedded processors could disagree with me). I think that because in my experience the performance improvement is much harder to achieve than compilation speed and code size improvements. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 16:16 ` Vladimir Makarov @ 2009-05-13 17:59 ` Jan Hubicka 2009-05-13 18:11 ` Michael Meissner 2009-05-15 20:19 ` Toon Moene 1 sibling, 1 reply; 30+ messages in thread From: Jan Hubicka @ 2009-05-13 17:59 UTC (permalink / raw) To: Vladimir Makarov Cc: Paolo Bonzini, gcc, Joseph S. Myers, Chris Lattner, Evan Cheng > Paolo Bonzini wrote: > > > >Rather, we should seriously understand what caused the compilation time > >jump in 4.2, and whether those are still a problem. We made a good job > >in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with > >speedups from other changes; and 4.4 while slower than 4.3 at least > >stays below 4.2. But, 4.2 was a disaster for compilation time. > > > > > It was interesting for me that GCC4.4 is faster than GCC4.3 on Intel > Core I7. This is not true for most other processors (at least for P4, > Core2, Power4/5/6 etc). Intel Core I7 has 3rd level big and fast cache > and memory controller on the chip. I guess that slowdown in GCC is > mostly because of data and/or code locality. Note that one of important reasons for slowdowns is the startup cost. Binarry is bigger, we need more libraries and we do more initialization. With per-function flags via attributes, we are now initializing all the builtins and amount of builtins in i386 backend has grown to quite extreme sizes. In 4.3 timeframe I did some work on optimizing startup costs that translated quite noticeably to kernel compilation time. It might be interesting to consider some scheme for initializing them lazilly. Honza > > Fortunately, GCC4.5 will be 5% faster because of Richard Guenter's work > on improving aliasing (of course if it will be not eaten by a new > optimization). People are complaining about GCC compilation speed and > of course we should work on its speedup. But GCC is not so bad, for > example SUN Studio compiler is almost 2 times slower than GCC. IMHO, > GCC performace is still #1 priority for us (although people working on > embedded processors could disagree with me). I think that because in my > experience the performance improvement is much harder to achieve than > compilation speed and code size improvements. ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 17:59 ` Jan Hubicka @ 2009-05-13 18:11 ` Michael Meissner 0 siblings, 0 replies; 30+ messages in thread From: Michael Meissner @ 2009-05-13 18:11 UTC (permalink / raw) To: Jan Hubicka Cc: Vladimir Makarov, Paolo Bonzini, gcc, Joseph S. Myers, Chris Lattner, Evan Cheng On Wed, May 13, 2009 at 05:42:03PM +0200, Jan Hubicka wrote: > > Paolo Bonzini wrote: > > > > > >Rather, we should seriously understand what caused the compilation time > > >jump in 4.2, and whether those are still a problem. We made a good job > > >in 4.0 and 4.3 offsetting the slowdowns from infrastructure changes with > > >speedups from other changes; and 4.4 while slower than 4.3 at least > > >stays below 4.2. But, 4.2 was a disaster for compilation time. > > > > > > > > It was interesting for me that GCC4.4 is faster than GCC4.3 on Intel > > Core I7. This is not true for most other processors (at least for P4, > > Core2, Power4/5/6 etc). Intel Core I7 has 3rd level big and fast cache > > and memory controller on the chip. I guess that slowdown in GCC is > > mostly because of data and/or code locality. > > Note that one of important reasons for slowdowns is the startup cost. > Binarry is bigger, we need more libraries and we do more initialization. > With per-function flags via attributes, we are now initializing all the > builtins and amount of builtins in i386 backend has grown to quite > extreme sizes. In 4.3 timeframe I did some work on optimizing startup > costs that translated quite noticeably to kernel compilation time. It > might be interesting to consider some scheme for initializing them > lazilly. For C and C++ on x86/x86_64, the compiler does not create the decls for the builtin functions until it is compiling an ISA that supports the builtin. So on x86_64, it will create the sse and sse2 builtins by default, but not the sse4, sse5, avx builtins until you use the appropriate -m<xxx> flag or specify a target specific option in the attributes or pragmas. Yes, an initial version of my patches did create all of the nodes, but the August 29th checkin did restrict building the builtins to the ISA supported. Now, it does create the builtins all of the time for other languages, since they don't register the appropriate create a builtin function in external scope hook. However, that still leaves the compiler creating a lot of builtins that mostly aren't used. It may be useful to register names, and have a call back to create the builtin if the name is actually used. It certainly would eliminate a lot of memory space, and time in the compiler. -- Michael Meissner, IBM 4 Technology Place Drive, MS 2203A, Westford, MA, 01886, USA meissner@linux.vnet.ibm.com ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 16:16 ` Vladimir Makarov 2009-05-13 17:59 ` Jan Hubicka @ 2009-05-15 20:19 ` Toon Moene 1 sibling, 0 replies; 30+ messages in thread From: Toon Moene @ 2009-05-15 20:19 UTC (permalink / raw) To: Vladimir Makarov Cc: Paolo Bonzini, gcc, Joseph S. Myers, Chris Lattner, Evan Cheng Vladimir Makarov wrote: > People are complaining about GCC compilation speed and > of course we should work on its speedup. But GCC is not so bad, for > example SUN Studio compiler is almost 2 times slower than GCC. Well, outside of these comparisons, I often completely flatten my colleagues (at home and abroad) because I compile the full 10^6 lines of Fortran code HIRLAM weather forecasting system in less than 5 minutes on my quad core PC (using make -j8). That's using -O3 (i.e., including vectorization). -- Toon Moene - e-mail: toon@moene.org - phone: +31 346 214290 Saturnushof 14, 3738 XG Maartensdijk, The Netherlands At home: http://moene.org/~toon/ Progress of GNU Fortran: http://gcc.gnu.org/gcc-4.4/changes.html ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-12 18:05 ` Chris Lattner 2009-05-12 18:21 ` Vladimir Makarov 2009-05-12 18:29 ` Joseph S. Myers @ 2009-05-13 6:42 ` Steven Bosscher 2009-05-13 7:33 ` Paolo Bonzini 2 siblings, 1 reply; 30+ messages in thread From: Steven Bosscher @ 2009-05-13 6:42 UTC (permalink / raw) To: Chris Lattner; +Cc: Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng On Tue, May 12, 2009 at 7:45 PM, Chris Lattner <clattner@apple.com> wrote: > 2. You change two variables in your configurations: micro architecture and > pointer size. Would you be willing to run x86-32 Core i7 numbers as well? > LLVM in particular is completely untuned for the (really old and quirky) > "netburst" architecture, but I'm interested to see how it runs for you on > more modern Core i7 or Core2 processors in 32-bit mode. FWIW, GCC is also completely untuned for NetBurst. There isn't even a scheduler description for the P4, and there also isn't anything for the funny branch predictor. > 3. Your SPEC FP benchmarks tell me two things: GCC 4.4's fortran support is > dramatically better than 4.2's (which llvm 2.5 uses), and your art/mgrid > hacks apparently do great stuff :). Something like the "art hack" is in ipa-struct-reorg, but it is not enabled at any level. If gcc outperforms llvm on art by much, it's more likely that some important opportunities for art are being overlooked by llvm. There also isn't anything special done for mgrid, except predictive commoning (CSE around loops) which is not a hack, in the sense it is helpful for a lot of numerical code and triggers several times in things like generic Fortran blas/lapack routines. Hope this helps, Ciao! Steven ^ permalink raw reply [flat|nested] 30+ messages in thread
* Re: New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 2009-05-13 6:42 ` Steven Bosscher @ 2009-05-13 7:33 ` Paolo Bonzini 0 siblings, 0 replies; 30+ messages in thread From: Paolo Bonzini @ 2009-05-13 7:33 UTC (permalink / raw) To: Steven Bosscher Cc: Chris Lattner, Vladimir Makarov, gcc.gcc.gnu.org, Evan Cheng >> 3. Your SPEC FP benchmarks tell me two things: GCC 4.4's fortran support is >> dramatically better than 4.2's (which llvm 2.5 uses), and your art/mgrid >> hacks apparently do great stuff :). > > Something like the "art hack" is in ipa-struct-reorg, but it is not > enabled at any level. If gcc outperforms llvm on art by much, it's > more likely that some important opportunities for art are being > overlooked by llvm. > > There also isn't anything special done for mgrid, except predictive > commoning (CSE around loops) which is not a hack, in the sense it is > helpful for a lot of numerical code and triggers several times in > things like generic Fortran blas/lapack routines. Indeed, we have a couple of benchmark-inspired optimizations for SPEC2006 (division/modulo power-of-two, see PR26026; and ifcombine), and we optimize MATMUL (TRANSPOSE (A), B) which helps galgel a lot. But both of this may trigger quite a lot on other code, and LLVM also benefits from the galgel one :-) because it's done in the front-end. Paolo ^ permalink raw reply [flat|nested] 30+ messages in thread
end of thread, other threads:[~2009-05-28 21:05 UTC | newest] Thread overview: 30+ messages (download: mbox.gz / follow: Atom feed) -- links below jump to the message on this page -- 2009-05-12 16:27 New GCC releases comparison and comparison of GCC4.4 and LLVM2.5 on SPEC2000 Vladimir Makarov 2009-05-12 18:05 ` Chris Lattner 2009-05-12 18:21 ` Vladimir Makarov 2009-05-12 19:25 ` Chris Lattner 2009-05-12 22:48 ` Rafael Espindola 2009-05-12 19:41 ` Vladimir Makarov 2009-05-13 12:11 ` Duncan Sands 2009-05-13 12:38 ` Richard Guenther 2009-05-13 12:55 ` Joseph S. Myers 2009-05-13 13:51 ` Duncan Sands 2009-05-26 12:27 ` Chris Lattner 2009-05-26 13:48 ` Vincent Lefevre 2009-05-28 23:00 ` Joseph S. Myers 2009-05-13 20:06 ` Evan Cheng 2009-05-12 18:29 ` Joseph S. Myers 2009-05-12 18:42 ` Vladimir Makarov 2009-05-13 8:44 ` Andi Kleen 2009-05-13 9:56 ` Jakub Jelinek 2009-05-13 11:32 ` Paolo Bonzini 2009-05-13 11:35 ` Paolo Bonzini 2009-05-13 12:07 ` Andi Kleen 2009-05-13 12:23 ` Steven Bosscher 2009-05-13 12:27 ` Dave Korn 2009-05-13 15:14 ` Paolo Bonzini 2009-05-13 16:16 ` Vladimir Makarov 2009-05-13 17:59 ` Jan Hubicka 2009-05-13 18:11 ` Michael Meissner 2009-05-15 20:19 ` Toon Moene 2009-05-13 6:42 ` Steven Bosscher 2009-05-13 7:33 ` Paolo Bonzini
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox; as well as URLs for read-only IMAP folder(s) and NNTP newsgroup(s).
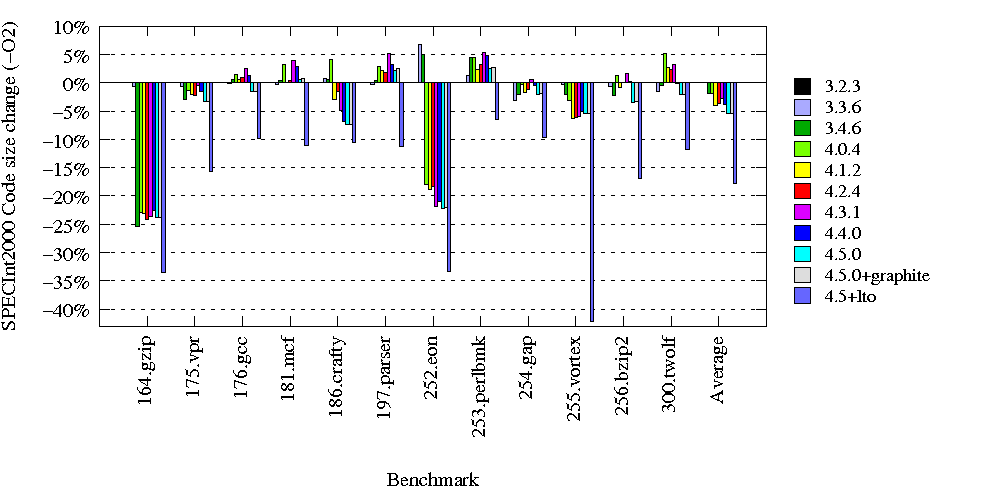{kind=link}
{kind=link}
{kind=link}